



编码、换行、注释与Git的四重奏——记一次C++编译失败问题的排查经历
背景
故事要从一年前说起。
在一次团队协作中,我想从远端Git仓库拉取一份C++项目代码,做一些修改然后编译。由于我使用的是一台新电脑(Windows系统),所以需要安装Git和Visual Studio等工具。我像一直以来那样,按照自己的习惯安装并配置了这些工具,然后用git clone拉取项目,用Visual Studio打开项目。结果代码并不能通过编译,报了很多错误和文件编码相关的警告。
我当时由于并不是一定要修改这份代码,所以简单排查后就搁置了,只当是有某些工具的版本或配置与团队不一致导致的问题。直到最近,我又换了一台新电脑,再次遇到这个问题时,我决定彻底解决它。
问题描述
使用Visual Studio编译C++代码时,输出很多错误和警告。根据直觉,其中最值得注意的是以下两类:
| 严重性 | 代码 | 说明 |
|---|---|---|
| 警告 | C4819 | 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失 |
| 错误 | C2065 | “xxx”: 未声明的标识符 |
初步分析
根据错误信息,可以初步判断问题来源于代码中含有编译器不能识别的字符。用Visual Studio Code等工具打开C4819警告所在的文件,确认文件是用UTF-8无BOM编码保存的。而936代码页表示的编码为GB 2312,按微软官方文档的说法:
在不能表示文件中所有字符的代码页的系统上编译 ANSI 源文件时,出现 C4819。
这说明MSVC编译器在读取源代码文件时使用的编码是系统的ANSI编码,在中文环境就是GB 2312。而如果源代码文件使用的是UTF-8编码,其中包含的某些字符(如中文)在GB 2312中没有对应的表示,就会导致编译器无法识别这些字符,从而产生C4819警告。
微软官方文档还贴心地给出了解决方案:
有多种方法可解决此问题。 一个简单的方法是删除冒犯字符,如果不需要该字符,比如它在批注中。 可以将“控制面板”中的系统代码页设置为支持源代码使用的字符集。 可以使用 Unicode 转义序列创建仅使用源代码中基本 ANSI 字符集的字符或字符串。 最后,可以使用签名以 Unicode 格式保存文件,也称为字节顺序标记 (BOM)。
若要以 Unicode 格式保存文件,请在 Visual Studio 中,选择 “文件”>“另存为”。 在“将文件另存为”对话框中,选择“保存”按钮旁的下拉菜单,然后选择“保存时使用编码”。 如果保存到同一文件名,可能需要确认要替换该文件。 在“高级保存选项”对话框中,选择可表示该文件中所有字符的编码(例如,Unicode(带签名的 UTF-8)- Codepage 65001,然后选择“确定”。
根据这套解决方案,我当时写了一个脚本,读取项目中的代码文件,识别文件的编码,然后保存为有BOM的UTF-8编码。在有BOM的情况下,MSVC编译器就不再用ANSI字符集,而是用UTF-8字符集读取源代码文件。
这样做虽然能解决编码问题,但是另外一些问题随之而来:
- 修改文件编码也就是修改源文件,会产生大量Git更改,留在工作区很不美观,提交到远程仓库也不方便。
- 如果有很多项目或项目中有很多文件,处理起来会非常耗时。
- 为什么只有我的环境会出问题,用其他人的电脑就能通过编译。
寻找其他方案
为了解决上述问题,我决定放弃修改源代码的文件编码,转而从环境入手,看看到底是哪里配置的问题。
检查Visual Studio版本
最开始我以为是因为自己装的Visual Studio版本与其他人不一致,导致编译过程有所不同。但检查后发现,版本虽然不是完全一致,但是也很接近,不应该有能够导致编译失败的问题。
修改编译选项
MSVC有一个编译选项可以指定源字符集,即/source-charset(另外还有两个相关的选项,一个是/execution-charset,另一个是/utf-8)。
尝试配置/source-charset:utf-8编译选项,但还是不行,会出现另一个问题:项目中另一些用GB 2312编码的源文件无法编译了(一个项目里居然能同时出现UTF-8无BOM、UTF-8有BOM、GB 2312三种编码的源文件☹️)。
修改系统语言环境
Windows中存在一个实验性选项,可以将系统的字符集改为UTF-8,于是尝试修改了这个选项。
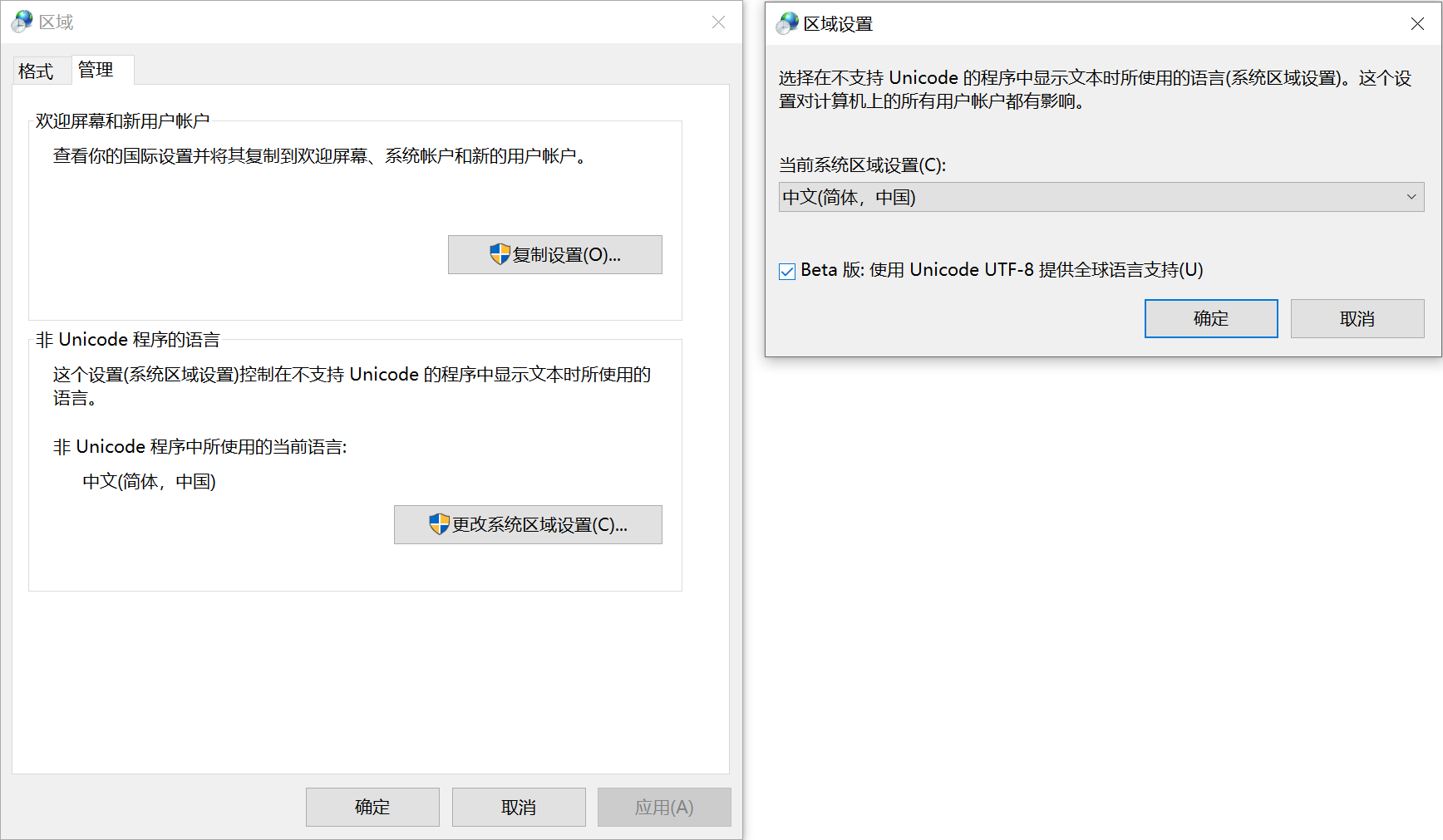
但这就和配置MSVC的/utf-8选项一样。而且问题更大,会导致已经编译好的程序执行出错,例如读取不到中文路径下的文件。
让我们冷静思考一下
经过一番折腾,我觉得从编码上解决这个问题是很难的(虽然这是彻底解决问题的方法)。我想,既然这个项目里存在编码混乱的情况,那应该有某种在编码混乱时也能通过编译的方法。
通过观察项目中的文件和其他人的电脑,我发现了以下几个现象:
- 在其他人的电脑上编译时,也会报C4819字符集警告,但是不会出现C2065错误。
- 并不是所有含中文且编码为UTF-8无BOM的代码编译都会报错。
- 代码中仅注释含有中文,非注释的逻辑部分不含中文。
在同事用file命令对比文件格式时,我终于捕捉到了决定性的差异:
- 大多数源文件在我这里用的是LF换行符,而在其他人那里用的是CR+LF换行符。
关于换行符,可以参考维基百科的解释:
应用软件以及操作系统对于换行字符的表示方式:
- 以ASCII为基础的或兼容的字符集使用分别LF(Line feed,
U+000A)或CR(Carriage Return,U+000D)或CR+LF;下面列出各系统换行字符编码的列表
- LF:在Unix或类Unix系统(GNU/Linux,AIX,Xenix,Mac OS X,...)、BeOS、Amiga、RISC OS
- CR+LF:DOS(MS-DOS、PC-DOS等)、微软视窗操作系统(Microsoft Windows)、大部分非Unix的系统
- CR:Apple II家族,Mac OS至版本9
简单来说,LF是Linux常用的换行符,长度为1个字节;CR+LF是Windows常用的换行符,长度为2个字节。
这让我意识到,可能由于编码问题,导致编译器在识别换行时出现错误,进而导致编译器将部分逻辑代码判断为注释,最终导致编译错误。
故事讲到这里,(奇怪的)经验丰富的读者应该可以推理出问题的原因了(提示:结合本文标题)。
究竟发生了什么
这里以一段C++代码为例,阐述问题背后的机理。
#include <cstdio>
int main() {
// 这里是中文
int a = 100;
printf("a = %d\n", a);
return 0;
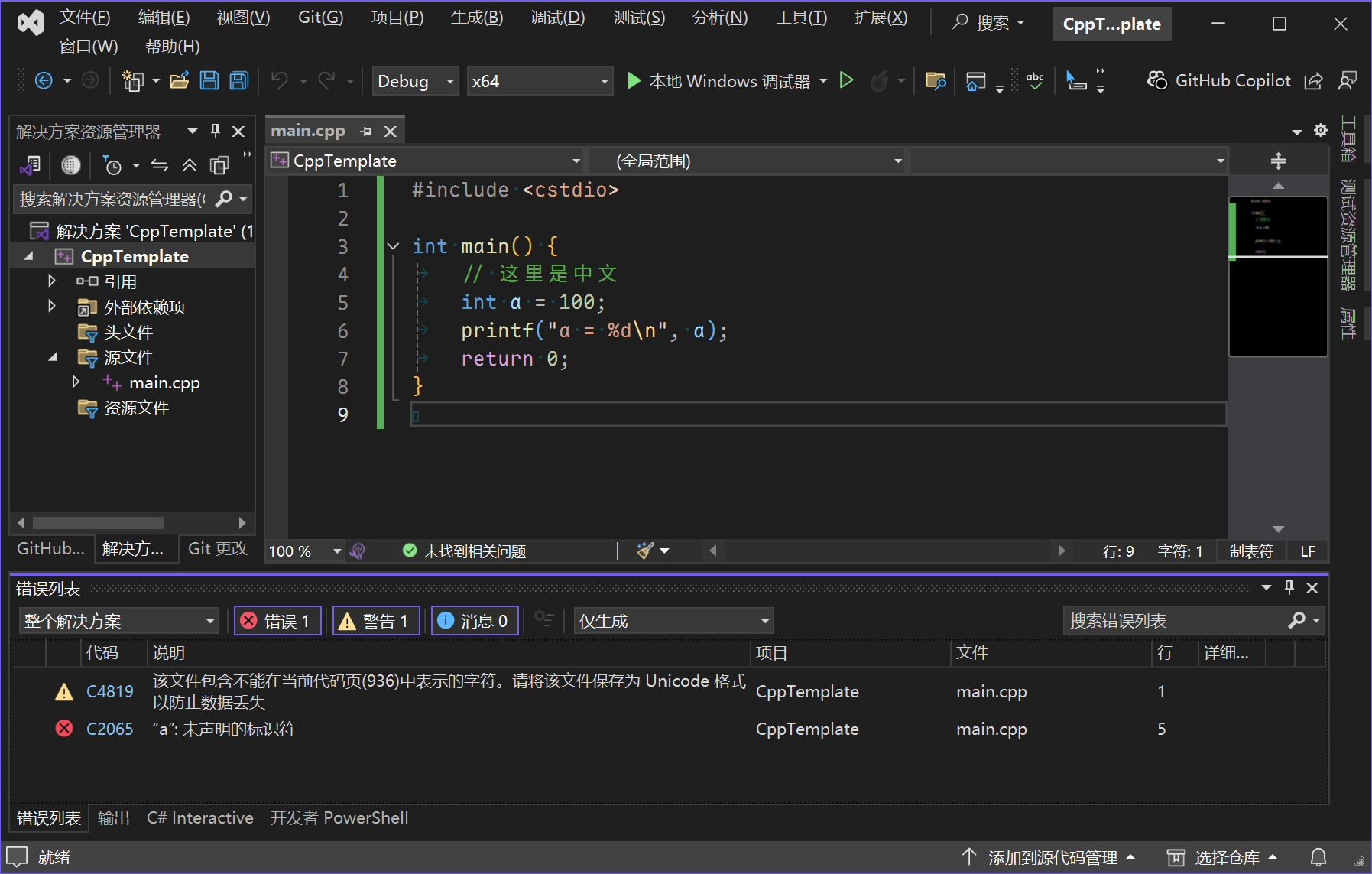
}问题复现
读者可以尝试将这段代码用UTF-8无BOM编码、换行符为LF的格式保存,然后用MSVC编译,就能复现故事中的问题:
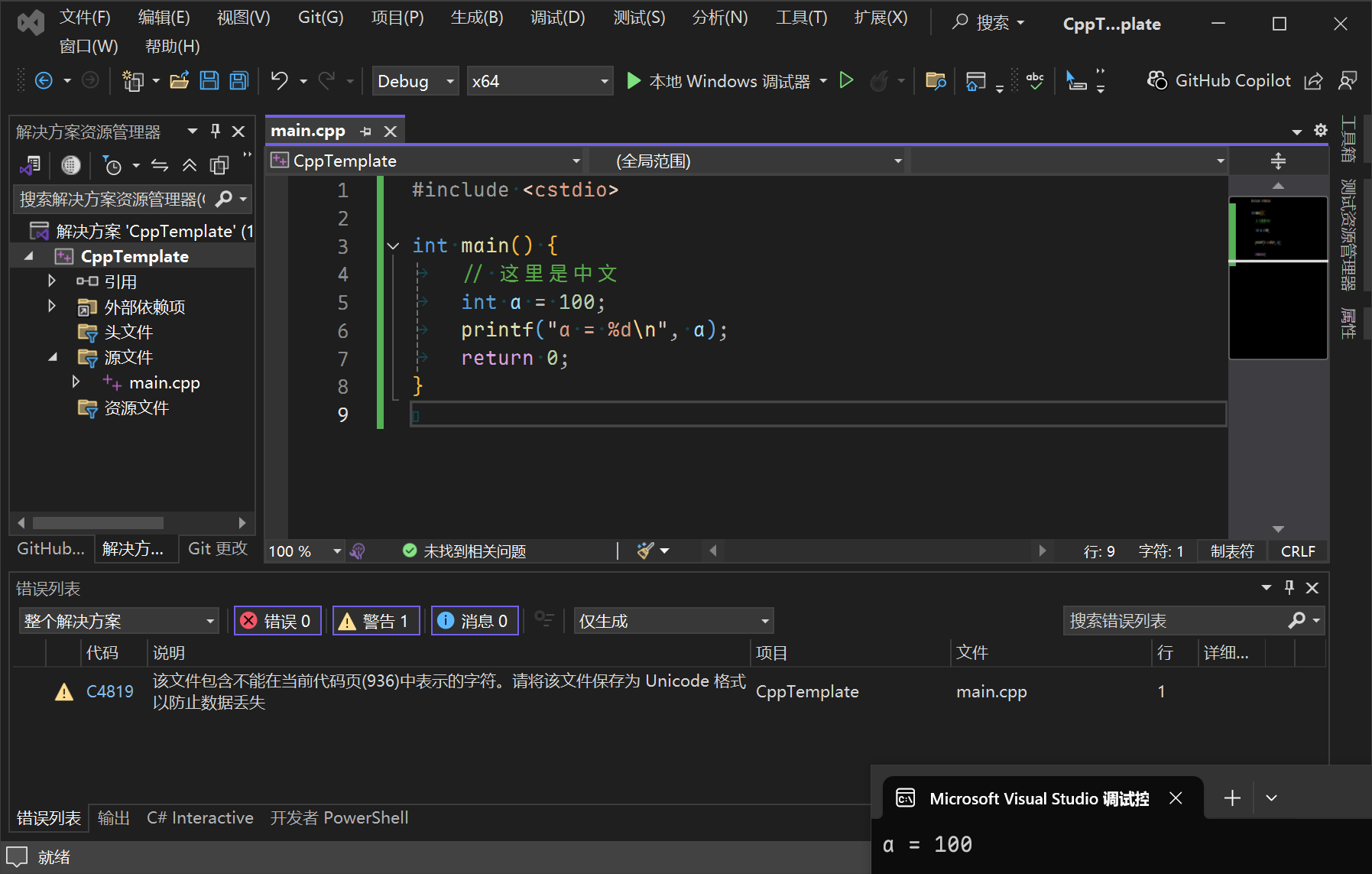
将换行符改为CR+LF,警告依然存在,但不会有错误,程序能够运行:
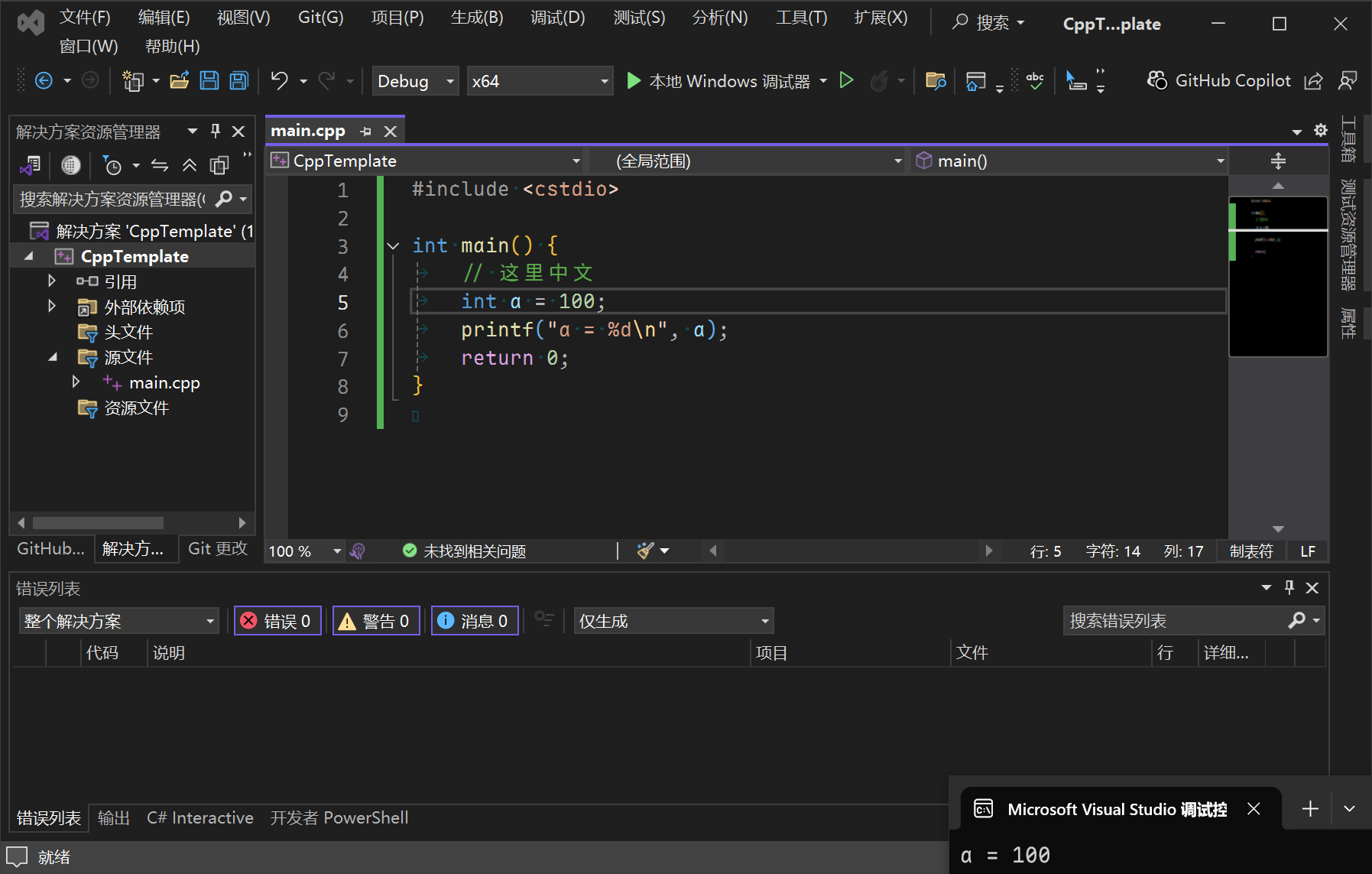
将换行符改回LF,然后将注释中的中文字符数量改为偶数,例如删去“是”字:
#include <cstdio>
int main() {
// 这里中文
int a = 100;
printf("a = %d\n", a);
return 0;
}这时,警告和错误都会消失,程序能够运行:
UTF-8和GB 2312的编码格式
要想知道为什么中文字符数量和换行符会导致编译出错,需要对UTF-8和GB 2312编码格式有基本了解,这里引用一些维基百科的说明。
UTF-8:
在ASCII码的范围,用一个字节表示,超出ASCII码的范围就用字节表示,这就形成了我们上面看到的UTF-8的表示方法,这样的好处是当UNICODE文件中只有ASCII码时,存储的文件都为一个字节,所以就是普通的ASCII文件无异,读取的时候也是如此,所以能与以前的ASCII文件兼容。
大于ASCII码的,就会由上面的第一字节的前几位表示该unicode字符的长度,比如110xxxxx前三位的二进制表示告诉我们这是个2BYTE的UNICODE字符;1110xxxx是个三位的UNICODE字符,依此类推;xxx的位置由字符编码数的二进制表示的位填入。越靠右的x具有越少的特殊意义。只用最短的那个足够表达一个字符编码数的多字节串。注意在多字节串中,第一个字节的开头"1"的数目就是整个串中字节的数目。
ASCII字母继续使用1字节存储,重音文字、希腊字母或西里尔字母等使用2字节来存储,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。
在UTF-8+BOM格式文件的开首,很多时都放置一个U+FEFF字符(UTF-8以EF,BB,BF代表),以显示这个文本文件是以UTF-8编码。
GB 2312:
在 GB 2312 内,每个汉字及符号的码位使用两个字节来表示。第一个字节称为“高位字节”,对应分区的编号(把区位码的“区码”加上特定值);第二个字节称为“低位字节”,对应区段内的个别码位(把区位码的“位码”加上特定值)。
也就是说,对于常用中文字符,UTF-8编码长度为3个字节,GB 2312编码长度为2个字节。
这意味着,如果用UTF-8编码保存偶数个中文字符,那么就有可能用GB 2312编码强行解码,且解码出的字符数量是源字符数量的1.5倍。

而如果用UTF-8编码保存奇数个中文字符,则大概率不能用GB 2312编码强行解码,否则结尾处会多出一个字节,或者说,缺少一个字节。

MSVC对字符解码与换行的处理
显然MSVC并不respect换行符,而是在强行解码源文件时将奇数个中文后面的字节补到了前面。也就是说,在注释中有UTF-8编码的奇数个中文字符的情况下,其后的换行符会被吞掉。
对于使用1个字节的LF换行符来说,换行符会被吞掉:

对于使用2个字节的CR+LF换行符来说,换行符会被神奇地保留一半:

于是,在使用LF换行符的情况下,中文注释(字符数量为奇数)后的一行会被编译器认为是注释的一部分,例如示例中的
int a = 100;被认为是
// 这里是中文的同一行,于是对这行代码“视而不见”,最终导致了故事中的C2065未声明标识符错误。而在使用CR+LF换行符的情况下,LF恰好能被保留下来,最终使得代码能够正确编译。
为什么我的换行符与其他人不同
问题的底层原因已经知道了,最后要解决的就是问题产生的直接原因,也就是为什么大多数源文件在我这里用的是LF换行符,而在其他人那里用的是CR+LF换行符。
这个问题的原因是Git的core.autocrlf配置。由于我一直在多个操作系统上进行开发,会注意编写代码时的行尾,所以在安装Git时,会统一把core.autocrlf设置为false。但是,其他人在Windows上安装Git时,默认配置为true。相关配置可以用git config --list命令查看。
关于core.autocrlf,可以参考官方文档:
假如你正在 Windows 上写程序,而你的同伴用的是其他系统(或相反),你可能会遇到 CRLF 问题。 这是因为 Windows 使用回车(CR)和换行(LF)两个字符来结束一行,而 macOS 和 Linux 只使用换行(LF)一个字符。 虽然这是小问题,但它会极大地扰乱跨平台协作。许多 Windows 上的编辑器会悄悄把行尾的换行字符转换成回车和换行, 或在用户按下 Enter 键时,插入回车和换行两个字符。
Git 可以在你提交时自动地把回车和换行转换成换行,而在检出代码时把换行转换成回车和换行。 你可以用
core.autocrlf来打开此项功能。 如果是在 Windows 系统上,把它设置成true,这样在检出代码时,换行会被转换成回车和换行:
$ git config --global core.autocrlf true如果使用以换行作为行结束符的 Linux 或 macOS,你不需要 Git 在检出文件时进行自动的转换; 然而当一个以回车加换行作为行结束符的文件不小心被引入时,你肯定想让 Git 修正。 你可以把
core.autocrlf设置成input来告诉 Git 在提交时把回车和换行转换成换行,检出时不转换:
$ git config --global core.autocrlf input这样在 Windows 上的检出文件中会保留回车和换行,而在 macOS 和 Linux 上,以及版本库中会保留换行。
如果你是 Windows 程序员,且正在开发仅运行在 Windows 上的项目,可以设置
false取消此功能,把回车保留在版本库中:
$ git config --global core.autocrlf false
也就是说,其他人在编写代码时,本地检出代码的换行符为CR+LF,提交上去又被自动转换为LF。而我在克隆检出后,由于没有开启自动转换,所以换行符是LF。
最终解决方案
综上所述,我最后像其他人一样把Git的core.autocrlf配置为true,然后重新克隆仓库,成功通过编译。
总结
本质上,这是一次编解码字符集不一致导致的问题。程序员在保存代码时使用的编码是UTF-8,而编译器在读取文件时使用的编码是GB 2312。然而,最后解决问题却没有解决编解码字符集不一致的问题,而是通过Git自动修改换行符规避了编译报错的问题。正所谓“治标不治本”,我不知道如果遇上更特殊的字符会不会产生其他问题,不知道如果中文字符出现在代码的其他位置会耽误多少程序员多少时间处理更奇怪的bug。
也许我之后可以写个脚本,将我们的代码都转换为统一的编码,例如带BOM的UTF-8。但是,类似的问题就像乌云一样笼罩在世界各地。我记得有些程序员笑话说的就是“代码删掉一个空行就跑不了”,也许背后就是类似的问题与血泪。Unicode为解决编码问题而生,但我们要建好并用好它,还需要付出无数的努力。
 编码、换行、注释与Git的四重奏——记一次C++编译失败问题的排查经历 by 長門有希 is licensed under Creative Commons Attribution 4.0 International
编码、换行、注释与Git的四重奏——记一次C++编译失败问题的排查经历 by 長門有希 is licensed under Creative Commons Attribution 4.0 International 
 .
.