



上下文词嵌入(Contextualized Word Embedding)总结
两个星期前我上传了静态词嵌入的总结,这次是上下文词嵌入(contextualized word embedding)的总结,包含一些预训练模型。PPT可以点击此处下载。
前言
在NLP领域中,一个重要的问题是如何表示词。在过去,有一些基于分布假说的Static Word Embeddings模型,如Word2vec和GloVe,他们利用词语的上下文分布信息学习每个词的静态嵌入表示,最后得到每个词对应的固定的向量。这种模型的缺点也很明显,第一是不能提现词语的多义性。尽管有一些基于上下文学习一个词对应多个词嵌入的方法,但是这些表示仍然是静态的,不能从根本上处理丰富的词义变化;第二是要将Static Word Embeddings应用到下游任务(例如Named Entity Recognition、Sentiment Analysis)时,还须要设计额外的分类模型,使用RNN或多层CNN再次获得当前的语境信息。
Contextual word embedding模型不再单独训练每个词的表示,而是以语境为单位,每次都输入完整的上下文,输出这些词在当前语境下的表示,并且同一个词在不同的语境中的表示是可变的。这样一方面解决了词语多义性的问题,另一方面通常无需再设计额外的下游任务模型,因为contextual word embedding已支持完整的上下文的输入输出。
本文首先介绍一个常用的特征提取模型Transformer (Vaswani et al., 2017),然后介绍contextual word embedding的训练过程,以及他们的评价方法和结果。
Transformer
Contextual word embedding的特点就在于其处理context的能力。Transformer对于序列元素间相关性的学习能力很强,为这一目标提供了基础结构。
Attention机制
机器学习的性能很大程度上取决于提取的特征。对于序列的特征提取,曾经有基于RNN的方法和基于多层CNN的方法,他们都是使用hidden state保留部分序列的信息,然后逐渐扩展到整个序列。然而正是由于他们从部分序列出发的特点,导致他们处理长距离依赖关系的能力较差。Attention的基本想法是,一次性计算序列间所有元素两两之间的相关性,这样就避免了长距离依赖的问题。
Attention的核心在于三个矩阵:Query (Q), Key (K)和Value (V),两个序列间的相关性就是Q和K的相似度。具体地说,设
其中m和n是两个序列的长度,为了保证与Transformer论文中的表达一致,都是行向量。那么Q和K的相关度有很多的计算方法,如
得到Q和K的相关度后,取softmax作为相关系数,然后求V的加权平均,就是attention的结果,即
很自然地可以想到,如果想寻找同一个序列内部每两个元素之间的相关性,那么只需让Q和K对应同一个序列即可,这就是self-attention。
以上是attention机制的数学运算过程。不过在此之前的问题是,如何得到QKV三个矩阵。对于self-attention来说,QKV就是对序列做不同的线性变换,且这个变换是可学习的。设输入的序列为
其中是行向量。那么
其中都是可学习的参数。
Multi-Head Attention
在Transformer模型中,每个attention层都是multi-head attention。Multi-head attention的概念是,在进行attention操作之前,将QKV分别投影多次,称为多个head,每个head独立进行attention,最后将每个attention的输出拼接起来作为multi-head attention的输出。
具体地说,我们通过将输入做线性变换得到了QKV,这时,我们再对QKV做h次投影,然后做h次attention,即
最后将h个结果concatenate,然后再做一次线性变换,保证输出的维度是想要的维度,即
其中。
Transformer Block
Transformer与常见的seq2seq模型相同,具有多层encoder和多层decoder。其中每个encoder层包括以下子层:
Multi-head attention
Feed forward网络
每个decoder层包括以下子层:
遮挡的multi-head attention
Multi-head attention
Feed forward网络
每个子层在其周围有一个残差连接,然后进行层归一化。残差连接有助于避免深度网络中的梯度消失问题。每个子层的输出是LayerNorm(x + Sublayer(x))。归一化是在d_model(最后一个)维度完成的。
Attention Mask
所谓的mask就是通过修改attention机制,使得每个Q不能attend到一些K。具体到Transformer模型中,mask分为两种,分别是padding mask和look ahead mask,其中所有的attention都要用到padding mask,只有每个decoder的第一个attention用到look ahead mask。
Padding mask的作用是对输入序列进行对齐。因为每个输入序列的长度是不同的,但是模型的参数个数是固定的,也只能接收定长输入,所以我们要在较短的序列后面填充0。而这些填充的位置没有意义,所以attention不应当处理这些位置,所以我们通过padding mask实现这个目的。
Look ahead mask的作用是阻止decoder看到未来的序列。由于序列是从左到右生成的,因此在训练过程中,decoder应该只能依赖于t时刻之前的输出,而不能依赖t时刻之后的输出。所以我们通过look ahead mask实现这个目的。除了look ahead mask以外,还需要将decoder的输入右移一位。
添加mask的方法如论文中的图所示,在scaled dot-product之后、softmax之前将它设为负无穷。
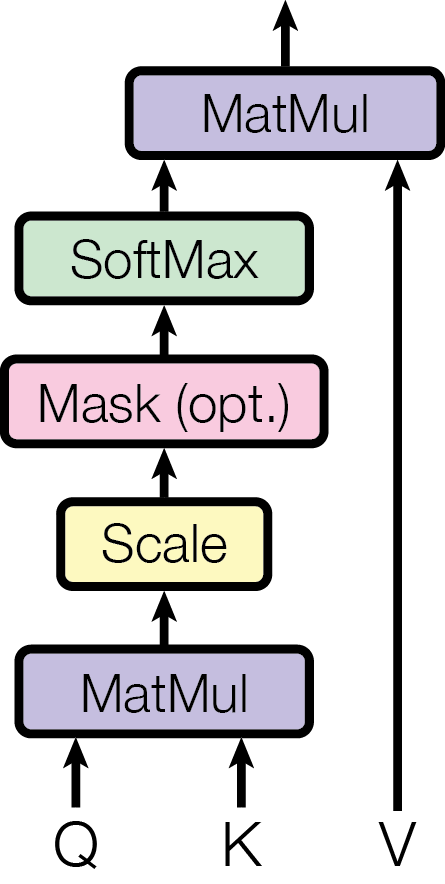
这样在softmax后,对于当前的Q,该位置的K的权重就是0,保证输出不包含该位置的V。
完整的原始Transformer模型
Transformer包括encoder、decoder和最后的线性层。
Encoder包括:
输入嵌入(Input Embedding)
位置编码(Positional Encoding)
N个encoder层
Decoder包括:
输出嵌入(Output Embedding)
位置编码(Positional Encoding)
N个decoder层
Decoder的输出是线性层的输入,最后返回线性层的输出。
Positional Encoding
Attention机制每次可以获得序列间所有元素两两之间的相关性,但是它的一个问题是不能获得序列元素的位置信息。传统的RNN结构由于是逐个元素输入的,所以它已经隐式地处理了元素的前后位置关系。而attention机制每次是计算embedding的相似度,并不包含这些embedding的前后位置关系。对于NLP任务,embedding的顺序信息代表了句子中的词语顺序,这是很有必要的。
为了解决这个问题,论文中使用了Positional Encoding,在embedding输入前加入它的位置编码,让模型能获得每个词的位置信息。论文中的编码公式为
对于任意的k,可以用线性表示。注意由于Positional Encoding和Word Embedding是直接向量相加的,所以他们两者的长度相同,均为。
线性层和输出预测
Decoder最终负责输出预测序列,为了实现这一点,我们将decoder的输出输入到一个线性层中,该线性层将维的向量重新投影到维上,经过softmax后,选择概率最高的一个词作为预测结果。
由于decoder使用了look ahead mask和shifted right,所以每个位置的输出都只包含encoder的完整序列和decoder已生成部分序列的信息,符合seq2seq的特点。
实验结果
实验分为三部分。第一是机器翻译。文中比较了Transformer和其他7个模型(含2个整合模型)的翻译性能(BLEU分值)和训练成本(FLOPs),其中大型Transformer模型比以前的最佳模型高出2.0个BLEU以上,而且训练成本比其他模型都要小。第二是测试了Transformer模型的变体,即各种超参数。主要结论是,在保持计算量不变的情况下,attention head的数量过多或过少都会有负面影响;模型的维度(包括嵌入大小、前馈层大小、key的大小)基本都是越大越好。第三是English constituency parsing。这个任务不是翻译,而是句法分析。虽然Transformer没有针对该特定任务调优,但是它的推断能力(WSJ 23 F1)接近之前最好的模型。
Contextual Word Embedding模型
Transformer的价值可能主要不是它的翻译能力,而是它的encoder和decoder结构,该结构可以获取输入序列隐含的相关信息。下面介绍的模型基本都采用Transformer的encoder或decoder作为模型的基础结构,具体包括六个模型:
Generative Pre-Training (GPT) (Radford et al., 2018)
Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2018)
Masked Sequence to Sequence Pre-training (MASS) (Song et al., 2019)
Unified Pre-trained Language Model (UNILM) (Dong et al., 2019)
XLNet (Yang et al., 2019)
BART (Lewis et al., 2019)
这六个模型大致可以分为两种结构,其中BERT、UNILM、GPT、XLNet可以看成多层Transformer Block或Attention的堆叠,最后输出是每个token的contextual embedding;MASS和BART可以看成完整的encoder-decoder结构,可以用于seq2seq任务。
训练过程
上面列出的contextual word embedding模型的训练过程都分为预训练和微调两步。
预训练
预训练(pre-training)过程的主要作用是利用大量无标注的语料,让模型的参数达到一个较好的状态,学习到一定的语义信息。上述的六个模型全部都使用了语言模型(Language Model, LM)任务作为预训练任务,另外BERT和UNILM还使用了下一句预测(Next Sentence Prediction, NSP)任务作为预训练任务。
LM任务
不同的模型结构对LM有不同的设计,但总体目标都是通过语境信息正确预测某些位置的token。
GPT是多层Transformer decoder堆叠的模型,它的特点是每个Q只能attend到它之前的K,所以是一个生成型的模型。因此GPT的预训练任务也是生成型的LM,每次输入语料库中k个词的词嵌入(加位置编码),输出第k+1个词的概率。这个过程与最早的神经语言模型(NNLM)类似。
BERT是多层Transformer encoder堆叠的模型,它的特点是没有look ahead mask,所以每两个词之间都可以进行attention操作。这种设计下,要实现LM,就必须对输入序列进行某种破坏,然后预测被破坏的部分。论文中设计了Masked Language Model (MLM),方法是,数据生成器随机选择15%的单词进行屏蔽(将token替换为[MASK]标记),然后把这些被屏蔽单词对应的最终输出向量送入词汇表的softmax实现预测。因为在后续微调过程中并没有[MASK]这种屏蔽标记,所以为了让训练过程与实际情况更一致,屏蔽单词的时候用了一点技巧,即如果选择了某个被屏蔽的单词,那么这个单词有80%的可能被替换为[MASK]标记,有10%的可能被替换为随机单词,有10%的可能保持不变。
MASS和BART都是完整的encoder-decoder,实际上他们都直接使用了完整的Transformer模型,只是在输入输出上做了一些处理。MASS的预训练方法类似于BERT的MLM,但是要求mask区域是连续的k个词。模型的encoder部分输入一个序列,其中用类似于BERT的策略mask掉其中连续的k个词,decoder的输入分为两部分,其中一个是encoder的输出经过attention的结果,另一个是已预测的序列,输出下一个预测的词,目标是使得被mask掉的词概率乘积最大。值得注意的是,这个模型中上下文信息主要来自于encoder,因为decoder输入的上下文是被mask掉的,只包含前面几个已预测的词,这样可以迫使decoder学习更多encoder编码表示的信息。BART与MASS的不同之处在于,它要求decoder部分预测完整的序列,而不仅仅是被mask的部分。这也使得它可应用于任意类型的文档破坏。极端情况下,当源文本信息全部缺失时,BART也等同于语言模型。论文中测试的几种文本破坏方法包括:
Token掩码:按照BERT模型,BART采样随机token,并用[MASK]替换它们。
Token删除:从输入中随机删除token。与token掩码不同,模型必须确定删除的位置。
文本填充:采样多个文本段,文本段长度取决于泊松分布(),用单个[MASK]替换这些文本段。如果采样的文本段长度为0,相当于插入一个[MASK]。
句子排列变换:按句号将文档分割成多个句子,然后以随机顺序打乱这些句子。
文档旋转:随机均匀地选择一个token,然后循环移位文档,使该token成为文档的开头。该任务的目的是训练模型识别文档真正的开头。
UNILM与BERT的结构基本相同,但是它在BERT的基础上添加了各种attention mask,因此可以用于更多类型的任务。它的预训练任务包含了单向LM(包括从左到右和从右到左)、双向LM和seq2seq LM,其中单向LM与GPT相同,双向LM与BERT相同。Seq2seq LM的训练方法是,将源序列和目标序列同时输入模型,作为句子对,随机遮蔽词后,预测源序列中的词时可以使用源序列所有的上下文,预测目标序列时只能使用源序列和目标序列左侧的上下文,这样符合序列生成的过程。
XLNet认为之前基于语言模型的预训练都有缺点,AR语言模型(如GPT)的缺点是无法同时利用上下文的信息,AE语言模型(如BERT)的缺点是在输入侧引入[MASK]标记,而微调阶段是看不到[MASK]标记的,导致预训练阶段和微调阶段不一致的问题。XLNet的训练语言模型的方法是,先随意打乱一句话的排列顺序,然后按照新的排列顺序通过AR语言模型进行预测。这样既可以让语言模型学到双向的上下文信息,又可以避免额外的标记导致的数据不一致的问题。具体实现方式是,不改变输入时句子的顺序,而是在逻辑上随机选择一种排列,将该排列末尾的几个词用attention mask屏蔽掉,然后逐一预测。
上面的想法比较直观,但是会导致另一个问题,就是在预测的时候不知道当前预测的位置。具体地说,设和是两种不同的下标排列,并且但,那么这两种排列分别在预测第个位置的时候就会出现
的情况。也就是说,虽然要预测的词不同,但是对于模型来说每个词的概率是相同的。这是因为输入的参数中没有这个值,导致模型不知道现在预测的词的下标是什么。为了引入当前下标的信息,论文中提出了two-stream self-attention的方法,其基本思想就是设计attention中的Q。对于原来的AR语言模型(如GPT),由于是顺序预测,所以只要用上一个embedding作为Q即可。而XLNet打乱了预测顺序,因此简单地使用上一个embedding是不可行的。Two-stream self-attention引入了一个可训练的embedding作为Q,而这个embedding在输入的时候带有Positional Encoding,这样就引入了当前预测位置的信息。
NSP任务
许多下游任务都需要支持两个序列同时输入,上述的六个模型中除了MASS以外都支持了这种设计,实现方法是将输入序列表示为
即把两个序列拼接起来,前后和中间各加一个特殊标记。既然引入了特殊标记,那么就要让模型学习到标记的含义。NSP任务就是为这一点设计的。
NSP的方法是,每次输入两个句子A和B,其中句子B有50%的可能是A在语料库中的下一句话,有50%的可能是从语料库中随机挑选的一句话。最后将[CLS]标记对应的输出向量送入分类层实现判别。
在这个任务中,模型利用[CLS]标记进行分类,并区分了[SEP]标记分割的两个句子,便于在后续的微调中继续使用这两个标记。
微调
与传统的Static Word Embeddings模型不同,contextual word embedding模型每次生成的词嵌入都是语境相关的。因此,contextual word embedding可以支持更多的下游任务,只需要将预训练好的模型再增加一个任务相关的结构,进行端到端的微调训练即可。
NLP任务可以分为自然语言理解(NLU)和自然语言生成(NLG)。其中NLU任务可以根据输出细分为序列分类(情感分类、逻辑推断、句子相似度)、token分类(命名实体识别)、获取输入的子串(提取型问答)三种。NLG任务的输出是sequence,包括机器翻译、文本摘要、生成型问答等。
上面所述的六个模型,除了MASS只支持NLG任务以外,其他五个模型都同时支持NLU和NLG任务。本文将按照输出的形式分类介绍微调方法。
序列分类
序列分类是指对一句话或两句话整体的分类或评分,例如SST-2的情感二分类任务和STSB的语义相似度五分类任务。这类任务微调的方法是取某个特定输入对应的输出embedding,将该embedding输入到分类层,通常该分类层就是一个全连接层加一个softmax。具体取哪个位置的输出是由模型结构确定的。对于BERT、UNILM和XLNet,他们可以支持双向的attention,所以可以取最前面[CLS]标记对应的输出embedding用于分类。对于GPT和BART,他们的输出层都是decoder,由于存在look ahead mask,所以只有最后一个token才能attend到整个序列,所以这两个模型是取最后一个token对应的输出embedding。
Token分类
Token分类是指对序列中的每个token进行分类,例如CoNLL-2003命名实体识别任务。这类任务微调的方法是将每个token对应的输出embedding输入到一个较小序列分类器中,如RNN或多层CNN,然后用传统的序列分类方法即可。虽然多加了一层序列分类器,但一般微调的过程还是端到端的,也就是说主体模型的参数也会调整。
获取输入的子串
这个类型的输出主要针对的是SQuAD问答任务,数据集中包含许多文本片段,每个片段对应一些阅读理解问题,这些问题的答案都节选自给定的文本片段。SQuAD 1.1包含十万个问题-答案对,SQuAD 2.0在此基础上增加了五万多个无法回答的问题,也就是说文本片段中不包含这些问题的答案,模型必须在回答前加以判断。
在微调过程中,每次将问题作为序列A,文本片段作为序列B同时输入到模型中。设置两个可学习的参数向量S和E,分别与序列B的每个输出embedding计算dot-product,目标是最大化
其中表示第i个token的输出embedding。
在测试时,计算,其中,选择这个分值最大的一对ij作为答案的起始和终止位置。
对于SQuAD 2.0,再额外计算一次S和E与[CLS]标记对应的输出向量C的内积作为无答案的分值,然后将这个值与有答案的分值进行比较,如果,那么就认为该问题有答案,其中是通过训练集选取的使F1分值最大的值。
Seq2Seq
在上述六个模型中,MASS、BART和UNILM是可以实现序列生成的。其中MASS和BART的结构与Transformer完全相同,微调方法也与Transformer的训练方法相同,这里不再重复。UNILM的seq2seq微调过程与seq2seq LM预训练过程类似,但是只随机遮蔽目标序列,不遮蔽源序列。值得注意的是,目标序列的结束标记[EOS]在微调过程中也可以被屏蔽,这样可以使模型学习何时生成[EOS]以结束目标序列的生成过程。
BART用于机器翻译
作为一个特例,BART没有把机器翻译看成普通的序列生成任务,而是把整个BART模型看成一个decoder,再添加一个小型随机初始化的encoder用于编码原文。这样做的原因是,预训练过程中BART的encoder和decoder都是用同一种语言进行的,那么在微调过程中如果直接输入另一种语言就显然不太合理。
训练分为两步:第一步,冻结大部分BART参数,只更新随机初始化的源encoder、BART的positional embeddings和BART encoder第一层的attention。第二步,对所有模型参数进行少量迭代训练。
Transformer的优化设计
Transformer作为encoder和decoder的特征提取和解码能力都比较强,这点在上述许多模型中都有所体现。不过也有一些基于Transformer的调整和设计,优化了它的训练过程或下游任务性能。
Transformer-XL
Transformer-XL (Dai et al., 2019) 解决了模型结构带来的上下文碎片的问题,使模型拥有了捕获更长距离依赖的能力。它的两个主要改进是段级循环机制(Segment-Level Recurrence Mechanism)和相对位置编码(Relative Positional Encodings)。
原始的Transformer引入了attention机制,使得模型能够直接捕获整个输入片段的每个词之间的依赖关系。但是原始的Transformer的最大输入长度是固定的,这导致它无法处理超出该范围的上下文长度。此外,固定长度的片段是通过选择连续的符号块来创建的,而没有使用句子或任何其他语义边界,导致上下文碎片的问题。段循环机制的方法就是每次将模型的隐状态保留下来,在下一时刻的attention过程中,每个Query不仅可以attend到该时刻其底层的Key,还能attend到上一时刻的Key。在测试过程中,Transformer-XL不需要像原始的Transformer那样为每一个位置重新做一次完整上下文的运算,而可以用段级循环机制每次预测完整的一段,大大提高了模型性能。
由于采用了段级循环机制,模型每次输入的一段就不再是从头开始的了,所以原始的绝对位置编码也不再适用。但是实际上我们大多时候只需要相对位置的信息,所以论文中提出了一种相对位置编码。与原始Transformer不同,该相对位置编码是在每一层的attention中加入的,而不是在初始嵌入中加入。设attention的Query的位置为i,Key的位置为j,那么就在attention分数中引入一个静态的相对位置编码来表达。
实验部分测试了模型在单词级别和字符级别上不同数据集的表现,并且与RNN和Transformer都做了比较。实验证明,Transformer-XL在各个不同的数据集上均实现了目前的SOTA,并且它的相对有效上下文长度(Relative Effective Context Length, RECL)、测试速度和文本生成能力都较为优秀。
ALBERT
ALBERT (Lan et al., 2019) 在BERT的基础上减少了参数量并提升了模型效果。它的主要设计分为三点:分解嵌入参数(Factorized embedding parameterization)、跨层参数共享(Cross-layer parameter sharing)和句间连贯性目标(Inter-sentence coherence loss)。
在原始的BERT中,输入词嵌入和Transformer内部隐状态向量的长度都是相等的,而论文认为这并不是必要的,因为理论上输入词嵌入只包含当前词的信息,而隐状态包含了上下文信息,所以隐状态应当比词嵌入复杂得多。而如果词嵌入使用了不必要的长度,由于词汇表大小较大,就会导致模型参数量过大。分解嵌入参数的想法就是直接缩小词嵌入的长度,然后用一个投影层在输入之前将词嵌入投影到隐状态的长度上。从后续的实验中来看,词嵌入的长度与实验效果也不是完全正相关。
跨层参数共享就是将原始BERT的多层Transformer Block的参数共享,而不是为每一层block训练新的参数。实验表明,参数共享可能会导致性能略有下降,但是并不明显。另外通过对比每层输入输出的L2距离和相似度,发现了BERT的结果比较震荡,而ALBERT比较稳定,跨层参数共享有稳定网络参数的作用。
许多研究都表明BERT的NSP任务的作用不大,甚至有可能具有负面影响。论文任务NSP任务无效的原因是该任务不够困难,模型可能会混淆主题预测和连贯性预测,而主题预测更容易学习。为了解决这个问题,论文引入了句子顺序预测任务,即判定输入的两句话是否被前后交换过。由于两句话都是同一篇文章中的内容,所以无法简单地通过主题来判断,而一定要学习句子间的连贯性才能完成。实验显示该任务能够提升下游任务的性能。
Evolved Transformer
Evolved Transformer (So et al., 2019) 使用神经结构搜索(Neural architecture search,NAS)的锦标赛选择(Tournament Selection)算法得到了更优秀的Transformer结构。
搜索过程以原始的Transformer结构出发,通过变换各种函数层生成后代,然后将后代中准确率最高的模型加入到种群中,进行下一轮迭代。
由于实验采用的是机器翻译数据集,所以如果进行完整的训练和验证会花费很多时间。因此论文中设计了一种渐进式动态障碍(Progressive Dynamic Hurdle)的测试方法。该方法在搜索开始时和锦标赛选择算法方法一致,在训练当前子代模型相对小的步数之后,评价适应度,然后根据现有的适应度选出合适的阈值,文中选取的是平均值,达到了阈值的子代会额外获得一定的训练步数,而没达到阈值的子代会被直接淘汰。这样的好处是,性能差的子模型在计算他们的适应度时不会消耗过多的资源。这可能会导致部分在训练后期优秀的子模型被丢弃,但是节省的资源提高了搜索的整体质量。
论文将通过搜索得到的最好的一个模型结构称为Evolved Transformer,并将该模型与原始的Transformer在不同任务不同参数情况下进行了比较。在相同参数下,Evolved Transformer有更好的性能,在相同性能下,Evolved Transformer只需要更少的参数。
Sandwich Transformer
如果把Transformer block中的结构拆开,可以看成是self-attention子层和feedforward子层的交替串接,称为交叉(interleaved)Transformer。但是Press et al. (2019) 提出,似乎并没有论证表明self-attention子层(s)和feedforward子层(f)交替就是最好的设计,可以尝试随机排列这两者来提高模型性能。
实验中作者探讨了两点:一个是s和f层的数量比例的问题,发现不均衡的模型并没有显著优于均衡的模型;另一个是s和f层排列先后的问题,实验中发现s偏底层而f偏顶层效果越好。实验中保证模型的参数量相同。
基于以上两种观察,论文设计了一种性能较优的结构,Sandwich Transformer,该结构将s层集中在底层,f层集中在顶层,中间加入s与f交叉的排列,写成公式形式为,其中n固定为16。通过测试不同大小的k值,发现k为6时模型在WikiText-103数据集上的perplexity最小。
最后论文在其他不同的任务上进行了实验,Sandwich Transformer虽然降低了语言模型的perplexity,但是没有在翻译任务上取得更优的结果。不过这种调整子层的方法可以在不额外增加参数和训练量的情况下提升一些模型性能。
Pre-LN Transformer
在原始的Transformer模型中,每个block的最后一个子层是Layer Norm子层,并且它处于残差连接之后,也就是说每个block的标注化操作是在最后单独进行的。Xiong et al. (2020) 提出,这种设计会导致模型初始的梯度过大,所以需要warm-up阶段来使用梯度下降法训练模型。而通过将Layer Norm子层移入到残差连接内部的最底层可以降低模型初始的梯度,从而可以删去warm-up阶段,以加速训练,减少超参数量。
论文中将原始的Transformer模型称为Post-LN Transformer,将Layer Norm子层移入到残差连接内部的模型称为Pre-LN Transformer。通过推导,得出结论,Post-LN Transformer中,最后的全连接层梯度的范围与Transformer的层数L无关,而在Pre-LN Transformer中,最后的全连接层梯度的范围与L成反比,所以这种结构下模型的层数越多在训练的初始阶段梯度下降就越稳定。
实验部分,论文在IWSLT14数据集上进行了Deutsche-English和English-Deutsche的翻译任务,以及MRPC和RTE两项下游任务,以验证Pre-LN的有效性。Pre-LN在训练时间和准确率方面结果均优于Post-LN。
BERT的优化设计
BERT作为一个典型的contextual word embedding模型,便于修改结构增加特性。目前有一些基于BERT结构的优化方法,如基于参数调整的RoBERTa (Liu et al., 2019),基于预训练LM任务优化的SpanBERT (Joshi et al., 2020)、StructBERT (Wang et al., 2019) 和ELECTRA (Clark et al., 2020),引入指导信息的模型SenseBERT (Levine et al., 2019) 和Weakly Supervised Knowledge-Pretrained Language Model (WKLM) (Xiong et al., 2019),以及针对低频词优化的BERTRAM (Schick and Schütze, 2019)。
基于参数的优化
RoBERTa (Liu et al., 2019) 针对BERT的一些细节进行了调整和测试。
第一是修改了BERT的Mask LM任务的mask方法。原始的BERT是在数据预处理阶段进行的mask,也就是说在整个训练期间的多个epoch中,每个词是否被mask是固定的。RoBERTa尝试将mask操作调整到输入时动态进行,这样每个epoch期间被mask的单词都是变化的。
第二是探索了NSP任务对模型结果的影响。共测试了4种训练方式:
SEGMENT-PAIR + NSP:这是原始BERT的做法。输入包含两部分,每个部分是来自同一文档或者不同文档的segment(segment是连续的多个句子)。预训练包含NSP任务。
SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子。预训练包含NSP任务。
FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token。预训练不包含NSP任务。
DOC-SENTENCES:输入只有一部分,类似于FULL-SENTENCES,只是不能跨越文档边界,其输入来自同一个文档的连续句子。预训练不包含NSP任务。
从结果上看,SEGMENT-PAIR优于SENTENCE-PAIR,可能是因为单个句子过短导致模型无法学习长距离依赖关系。而不使用NSP任务的结果比使用NSP任务的结果要好。
第三是尝试增大了预训练数据集和batch size。论文中通过实验证明了更大的数据集和batch size有助于提升性能。
修改LM任务的优化
有一些针对BERT Masked LM的简单修改,并取得了较好的效果。
SpanBERT (Joshi et al., 2020) 提出了一种Span Masking的方案和Span Boundary Objective (SBO) 的目标。Span Masking是指它不再随机mask词,而是每次挑选一段连续的词进行mask,这段mask区域的长度遵循几何分布。SBO是用Span Masking区域前后的两个词来预测该区域的所有词,即,其中和表示mask区域前后两个词的输出embedding,表示要预测的词在该mask区域的相对位置编码。最后模型的目标函数是MLM和SBO任务的目标之和,即
除此以外,SpanBERT也发现NSP任务会使得模型效果更差,作者推测这可能是因为单句训练可以让模型获得更长的语境,另外加入另一个文本的语境信息会带来噪音。
StructBERT (Wang et al., 2019) 在BERT的基础上增加了Word Structural Objective和Sentence Structural Objective两个目标。Word Structural Objective的做法是,除了和BERT一样进行mask外,对未mask的词,随机抽选一个n-gram,打乱顺序后重构该顺序。Sentence Structural Objective的做法是,将原来NSP的二分类任务改为三分类,要求模型判断输入的两个句子在原文的关系是第一句在第二句前,或第一句在第二句后,或两个句子不是连续的。之所以会想到这种修改,是因为原来BERT的NSP任务太过简单,模型可以达到97%至98%的准确率,而更复杂的任务可能可以使模型训练更加充分。
ELECTRA (Clark et al., 2020) 将BERT的回归型LM改为判别型LM,即模型的最终目标是判断每个词是否被修改过的二分类任务,而不是生成被mask的词。这样的好处是每次训练都识别所有的词,而不像原始BERT那样只处理15%的词,并解决了BERT引入[MASK]标记导致预训练和微调不一致的问题。
这个替换的过程并不是人工替换或者随机替换,而是再训练一个小型的MLM,称为generator。在训练过程中,给generator输入带[MASK]的句子,generator生成对应位置的词。当然,由于模型较小,生成的词可能会有错误,而ELECTRA就利用这个错误的词。我们把ELECTRA当作discriminator,然后将generator的输出传递给它,ELECTRA判断每个词是否是原句中正确的词。
上述generator和ELECTRA是同时训练的,即参数每更新一步,MLM的loss和ELECTRA的loss都会更新。这种思路非常像GAN,但并不是真正的GAN,因为这两个模型并不是对抗性的,即如果generator生成了原本就是正确的词,那么我们希望ELECTRA的判别结果是original而不是replaced。这也就要求generator的效果不能太好。
引入指导信息的优化
SenseBERT (Levine et al., 2019) 在MLM任务中加入了语义信息,该语义信息是指WordNet定义的45种supersense(例如noun.animal、verb.contact)。具体做法是给每种supersense一个embedding,在输入时查WordNet中每个词对应的supersense有哪些,输入的embedding在原来word embedding的基础上再加上该词所有的supersense embedding。MLM的预训练任务中,除了要预测屏蔽词以外,还要预测屏蔽词的supersense。实验结果表示SenseBERT在基于SemEval的Supersense Disambiguation任务上显着优于常规BERT,并在Word in Context任务中实现了SOTA结果。
WKLM (Xiong et al., 2019) 在训练MLM任务的同时,通过识别被替换的实体名称训练了模型获取实体相关的信息的能力,训练过程称为Entity Replacement。该训练过程用Wikipedia作为语料库,在这个语料库中用Wikipedia的链接和Wikidata的实体别名来识别实体名称的单词和词组。在替换这些名称时,首先从Wikidata中查找与当前实体类型相同的实体,然后随机选取一个进行替换。需要注意的是,替换过程中需要保证连续的实体名称不被替换,也就是说任意两个被替换过的实体名称之间一定有没被替换过的实体名,这是为了避免一句话中所有实体都被替换了而恰好形成另一句正确表述的情况。Entity Replacement与MLM是同时训练的,MLM的[MASK]标记替换确保不在实体名称的内部。在训练时,对于每个实体,将它前后两个词的输出embedding连接后加一个线性层进行预测,类似于SpanBERT的SBO。实验证明WKLM在实体相关的任务和开放领域的QA任务中表现很好。
针对低频词的优化
BERTRAM (Schick and Schütze, 2019) 采用传统词嵌入的思想,用subword和context信息加强了低频词的表示。BERTRAM是一个比较大的模型,它的输入是一个低频词的n-gram和它的一些context,输出是一个non-contextualized word embedding,可以作为BERT的输入embedding。
BERTRAM的核心在于如何获取和结合subword和context信息。对于subword的处理比较简单,设一个向量是单词的所有n-gram subword embedding的平均即可。而处理context信息的方法,文中给出了三种,分别是SHALLOW、REPLACE和ADD。
为了介绍这三种方法,设单词w出现在上下文C中的第i个位置,序列是将C中的w替换为[MASK]后的序列,表示输出层的第j个向量。
SHALLOW的处理方法是用BERT计算,然后和加权求和。
REPLACE是用BERT计算,即把w替换为subword表示。然后作为单个上下文的最终表示。
ADD是在t的前面添加w的subword和冒号,即。然后作为单个上下文的最终表示。这样做的理由是可能语料库中含有很多词典类型的语料,他们的格式就是“词:解释”这样用冒号分隔的词语和解释,因此用相同的格式可能可以帮助模型提高训练效率。
上面三种方法得到了w在一个上下文中C的表示。但是w可能不止出现在C中,而出现在多个上下文中,所以需要计算w在多个上下文中的最终embedding。论文中用到了一个Attentive Mimicking的结构,它是利用self-attention计算输入的加权平均。所以最后w的embedding是
这篇论文的另一个贡献是提出了一种评测低频词模型的数据集的构造方法,称为Dataset Rarification。它的核心思想是找到数据集中的每一句的重要的词,然后把这个词替换为低频同义词。设数据集为D,其中每一项可以表示为,其中x是文本,y是分类的目标标签。另外我们有一个低频同义词词典S,表示把单词w转换为它的低频同义词集合。我们把D分为和,保证中的每一个句子x中都至少包含一个词w,使得不为空,也就是说的每条数据都能找到至少一个词来替换为低频同义词。然后用训练一个简单的模型,使他实现分类任务。然后用它测试的每一条数据,并把能替换为低频同义词的词逐个替换为[MASK]标记再测试。如果该模型能在原数据上正确分类,而在替换后分类错误了,说明这个词是这句话中比较重要的词。那么我们就把该词替换为一个随机的低频同义词,然后加入到新数据集中。这样我们就得到了一个包含低频词的数据集,并且这个数据集的任务与原数据集相同。
模型评价
NLP任务可分为NLU和NLG两类,这里列举一些常见的任务和数据集。
NLU:
GLUE Benchmark: 包括9项序列分类的任务 https://gluebenchmark.com/
SQuAD: 给定一篇文章和问题,答案是原文中的一段话 https://rajpurkar.github.io/SQuAD-explorer/
SWAG: 给定一个句子,在四个选项中选择最合理的下一句 https://www.aclweb.org/anthology/D18-1009/
CoNLL-2003: 命名实体识别 https://www.clips.uantwerpen.be/conll2003/ner/
NLG:
WMT: 神经机器翻译 http://statmt.org/wmt20/translation-task.html
Gigaword: 文本摘要 https://github.com/harvardnlp/sent-summary
Cornell Movie-Dialogs: 对话响应生成 https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html
NLU任务都是分类或打分任务,所以可以采用准确率、F1值和相关系数作为指标。Wang et al. (2020) 抓取了GLUE Benchmark的数据,绘制了以人类baseline的结果标准化后的图像。下图的横轴是各种模型和模型组合,按时间排序,纵轴是标准化后的评测结果。最新的XLNet-Large的GLUE综合分值已经超过了人类水平。
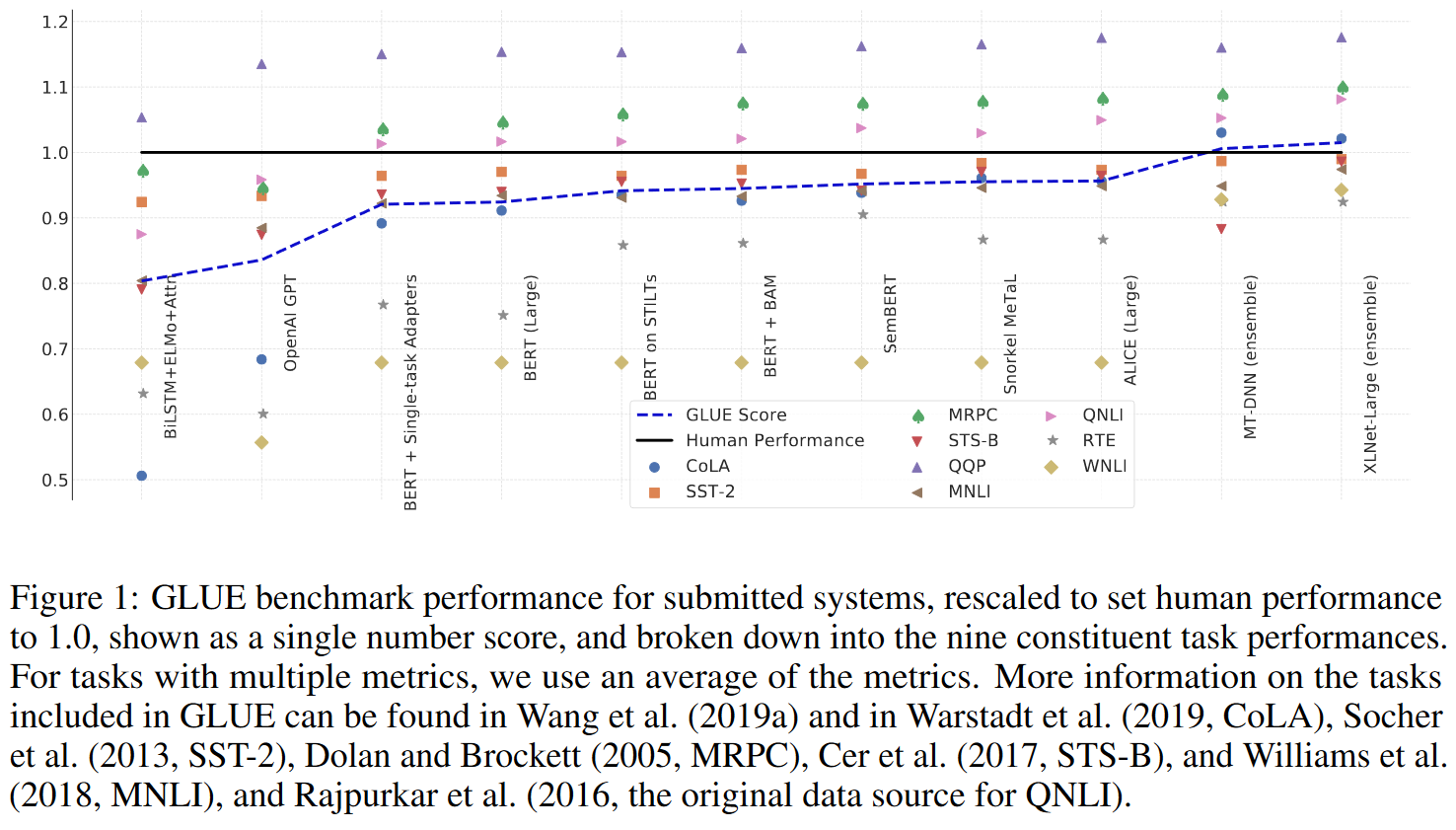
NLG任务的评测更复杂一点,因为生成型的任务不能简单地用准确率等指标来衡量,而可以采用BLEU、ROUGE、Perplexity等指标。按照习惯,机器翻译任务一般使用BLEU,文本摘要等有参考结果的任务一般使用ROUGE,对话响应生成等无参考结果的任务一般使用Perplexity。
Lewis et al. (2019) 对比了多个模型在文本摘要任务上的结果。其中本文涉及到的模型是UNILM和BART两者。
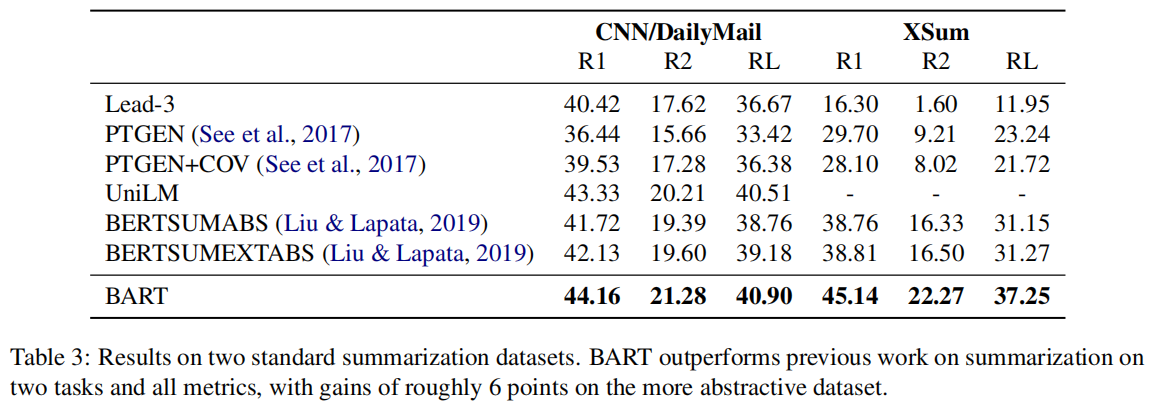
CNN/DailyMail和XSum是两个具有不同属性的摘要数据集,CNN/DailyMail中的摘要往往类似于原句,而XSum是高度抽象的。在所有ROUGE指标上,BART的性能均显著超过了以前最好的工作。
Ablation实验
本文涉及到的六个模型,除了UNILM以外,其余五篇论文都进行了ablation实验,中文可以翻译为消融实验。在机器学习领域,特别是复杂的深度神经网络的背景下,采用ablation实验,删掉模型的某一部分,与原模型对比,可以更好地理解网络的行为,证明某些设计的有效性。
GPT的ablation实验中对模型进行了三项修改,并测试了修改后的模型性能。这三项修改分别是:删除模型微调过程中的辅助语言模型目标,将Transformer更换为LSTM,和不进行预训练,直接训练有监督的目标任务。结果显示,辅助的语言模型目标在数据量大的情况下可能会有帮助,在数据量小的情况下没有什么影响;而其他两种修改都对模型产生了负面影响,说明了当前Transformer结构和预训练任务的有效性。
BERT进行了三个ablation实验。第一个ablation实验对比了BERT在“No NSP”“LTR & No NSP”“+ BiLSTM”三种情况下评估结果的变化,结果显示删除NSP会严重损害QNLI、MNLI和SQuAD 1.1的性能,使用单向的语言模型LTR在各个任务上的性能都比MLM差,说明深度双向模型是有必要的。第二个ablation实验测试了模型大小的影响,结果证明较大的模型可以使各项任务的性能都有提升,同时也证明了,如果模型经过了充分的预训练,那么在微调时即使训练数据不足,通过增大模型也可以达到较好的效果。第三个ablation实验删除了微调的过程,直接提取模型隐藏层的表示送入输出层。结果显示,即使没有微调过程,实际任务的结果也不会比有微调的模型低很多,这表明BERT对于微调和基于特征的方法均有效。
MASS的ablation实验针对模型的两个设计做了修改。第一是将模型的连续mask改为随机mask,第二是将decoder输入屏蔽上下文改为不屏蔽。结果发现这两种修改都导致模型性能下降,证明连续的mask可以使模型获得更好的语言建模能力,屏蔽decoder侧的上下文可以使decoder从encoder侧提取更多有用的信息。
XLNet的ablation实验发现,NSP任务在XLNet里并无作用。而去掉memory、span-based的预测和双向的数据时效果都是有所下降的,因此它们都是有用的。
BART的ablation实验比较了不同的预训练LM和文本破坏方法对模型性能的影响。结果发现,虽然在不同任务上不同的预训练任务性能差异较大,但是整体而言使用token masking和text infilling作为预训练任务时模型性能最好。这可能是由于该任务要求模型同时学习生成的词语和长度,使得模型更善于文本生成。
参考文献
Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. 2020. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555.
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. 2019. Transformer-xl: Attentive language models beyond a fifixed-length context. arXiv preprint arXiv:1901.02860.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unifified language model pre-training for natural language understanding and generation. In Advances in Neural Information Processing Systems, pages 13063--13075.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. 2020. Spanbert: Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics, 8:64--77.
Ashish Khetan and Zohar Karnin. 2020. schubert: Optimizing elements of bert. arXiv preprint arXiv:2005.06628.
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
Yoav Levine, Barak Lenz, Or Dagan, Dan Padnos, Or Sharir, Shai Shalev-Shwartz, Amnon Shashua, and Yoav Shoham. 2019. Sensebert: Driving some sense into bert. arXiv preprint arXiv:1908.05646.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Ofifir Press, Noah A Smith, and Omer Levy. 2019. Improving transformer models by reordering their sublayers. arXiv preprint arXiv:1911.03864.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under-standing by generative pre-training.
Timo Schick and Hinrich Schutze. 2019. Bertram: Improved word embeddings have big impact on contextualized model performance. arXiv preprint arXiv:1910.07181.
David R So, Chen Liang, and Quoc V Le. 2019. The evolved transformer. arXiv preprint arXiv:1901.11117.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2019. Mass: Masked sequence to sequence pre-training for language generation. arXiv preprint arXiv:1905.02450.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998--6008.
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2019. Superglue: A stickier benchmark for general-purpose language understanding systems. In Advances in neural information processing systems, pages 3266--3280.
Wei Wang, Bin Bi, Ming Yan, Chen Wu, Zuyi Bao, Jiangnan Xia, Liwei Peng, and Luo Si. 2019. Structbert: Incorporating language structures into pretraining for deep language understanding. arXiv preprint arXiv:1908.04577.
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. On layer normalization in the transformer architecture. arXiv preprint arXiv:2002.04745.
Wenhan Xiong, Jingfei Du, William Yang Wang, and Veselin Stoyanov. 2019. Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model. arXiv preprint arXiv:1912.09637.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pages 5753--5763.


